
tesseract ocr(图像识别类库)下载
 资源下载页
资源下载页
- 评分:★★★☆☆
- 时间:2021-05-09
- 大小:56M
资源下载页
tesseract ocr是原先惠普开发的图像识别类库,后面成为Open source,据说曾经的图像识别能力排名第三,为大家提供的版本是4.0.0 for windows。 使用方法 下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。安装完成后目录如下: tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。 如果出现如上输出,表示安装正常。 结果为: 附录:
附录:
使用Tessract-OCR引擎识别验证码
打开DOS界面,输入tesseract: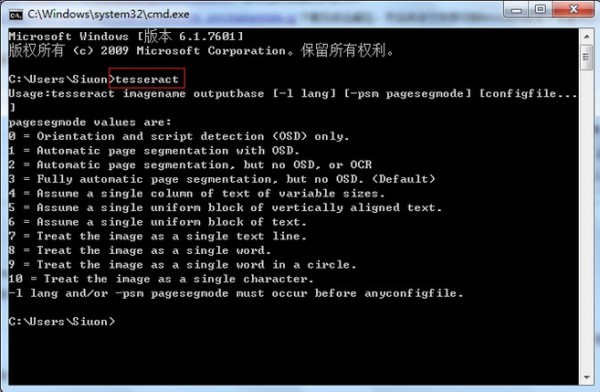
我准备了一张验证码 放在D盘根目录下,上图:
放在D盘根目录下,上图: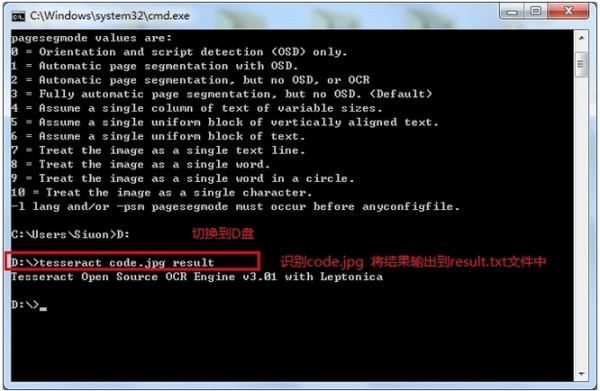
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
 C(Free官方版下载_C_Free下载 v5.0官方
C(Free官方版下载_C_Free下载 v5.0官方
 PageAdmin企业级网站内容管理系统下
PageAdmin企业级网站内容管理系统下
 三菱PLC编程软件(GX Developer)下载 v
三菱PLC编程软件(GX Developer)下载 v
 64位Java(Java Runtime Environment(JRE)下载
64位Java(Java Runtime Environment(JRE)下载
 Walle部署工具(Walle(开源部署工具)下
Walle部署工具(Walle(开源部署工具)下
 PLSQL中文汉化版(PL/SQL Developer中文版
PLSQL中文汉化版(PL/SQL Developer中文版
 Joomla内容管理系统(Joomla下载 v3.9.
Joomla内容管理系统(Joomla下载 v3.9.
 CuteFTP软件下载(Cuteftp下载 v9.3.0.3官
CuteFTP软件下载(Cuteftp下载 v9.3.0.3官
 instantclient 32下载(instantclient_basic(轻
instantclient 32下载(instantclient_basic(轻
 APK反编译工具合集(Apkdb)下载 v2.1.
APK反编译工具合集(Apkdb)下载 v2.1.
 jdk1.7官方下载64位(jdk1.7 64位下载 官
jdk1.7官方下载64位(jdk1.7 64位下载 官
 keil c51下载(Keil C51(51单片机编程软件
keil c51下载(Keil C51(51单片机编程软件
 FreeIconFinder(图标搜索器)下载 v1.3官
FreeIconFinder(图标搜索器)下载 v1.3官
 DedeCms V5.1下载 (GBK/UTF8)商业版(
DedeCms V5.1下载 (GBK/UTF8)商业版(
 Gitblit(开源git仓库)下载 v1.9.1官方版
Gitblit(开源git仓库)下载 v1.9.1官方版